# CataRT
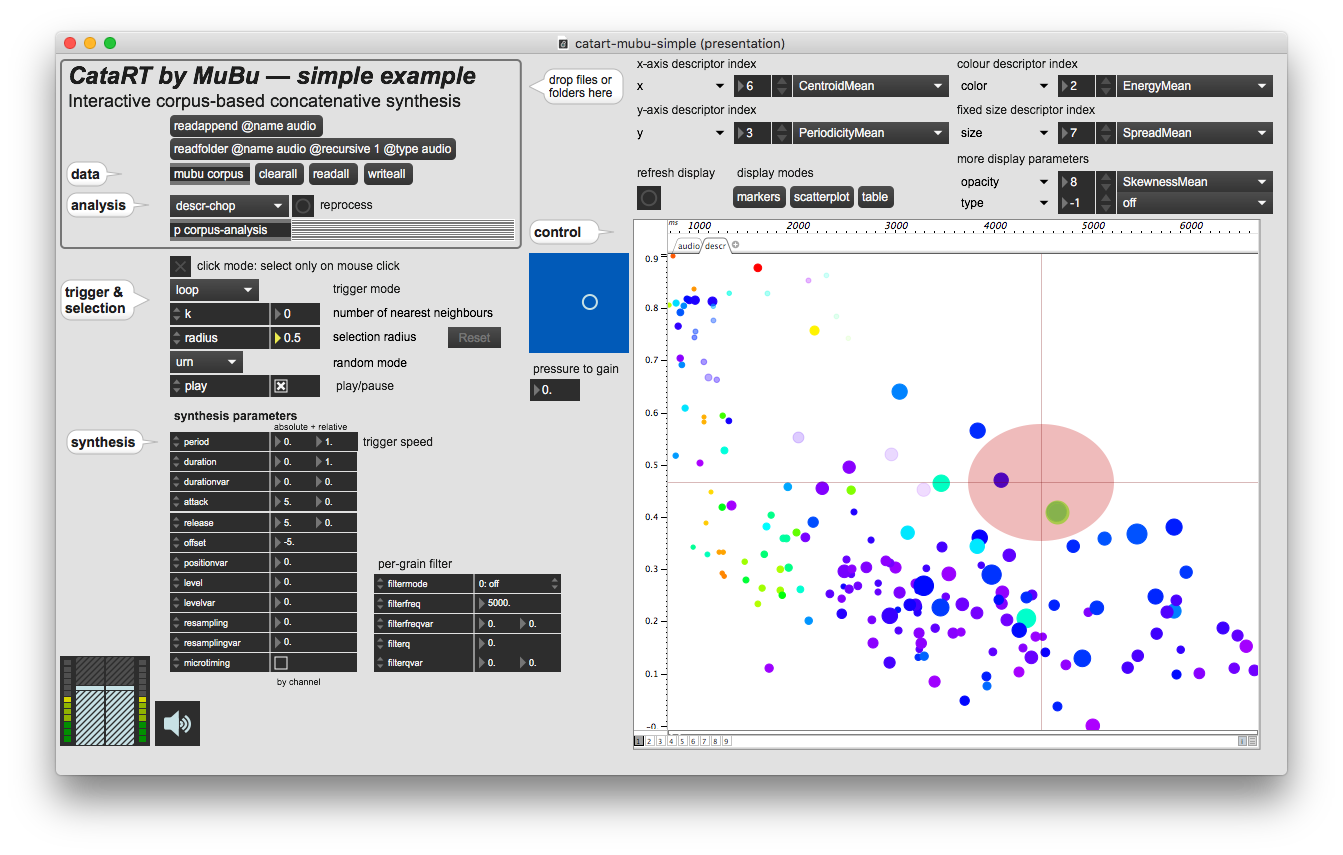
The concatenative real-time sound synthesis system CataRT, created in 2005, plays grains from a large corpus of segmented and descriptor-analysed sounds according to proximity to a target position in the descriptor space. This can be seen as a content-based extension to granular synthesis providing direct access to specific sound characteristics.
For instance, this allows to create expressive textural evolution using perceptual timbre descriptors, control of output grains by similarity to audio input (audio mosaicing or beat replacement), or juxtaposition of sounds from varying sources by timbral features.
The current CataRT comes in three flavours:
| CataRT-MuBu | patches for Max using objects from the MuBu library, and descriptor analysis via the PiPo framework |
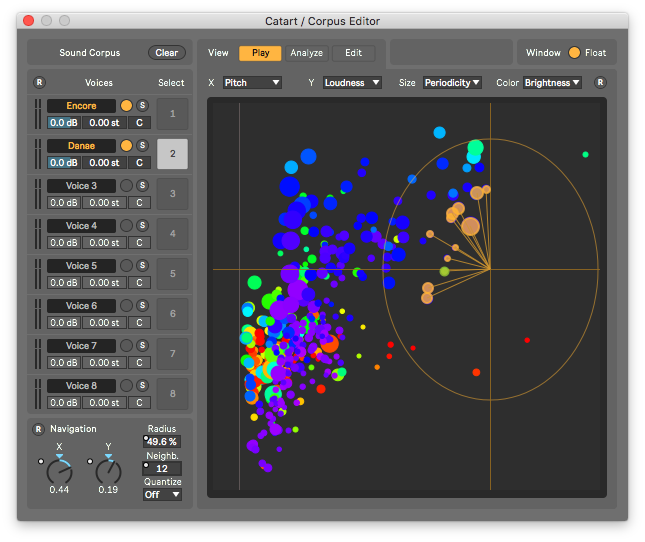 | SKataRT | Max4Live device for Ableton Live, on the Ircam Forum (Mac/Windows). |
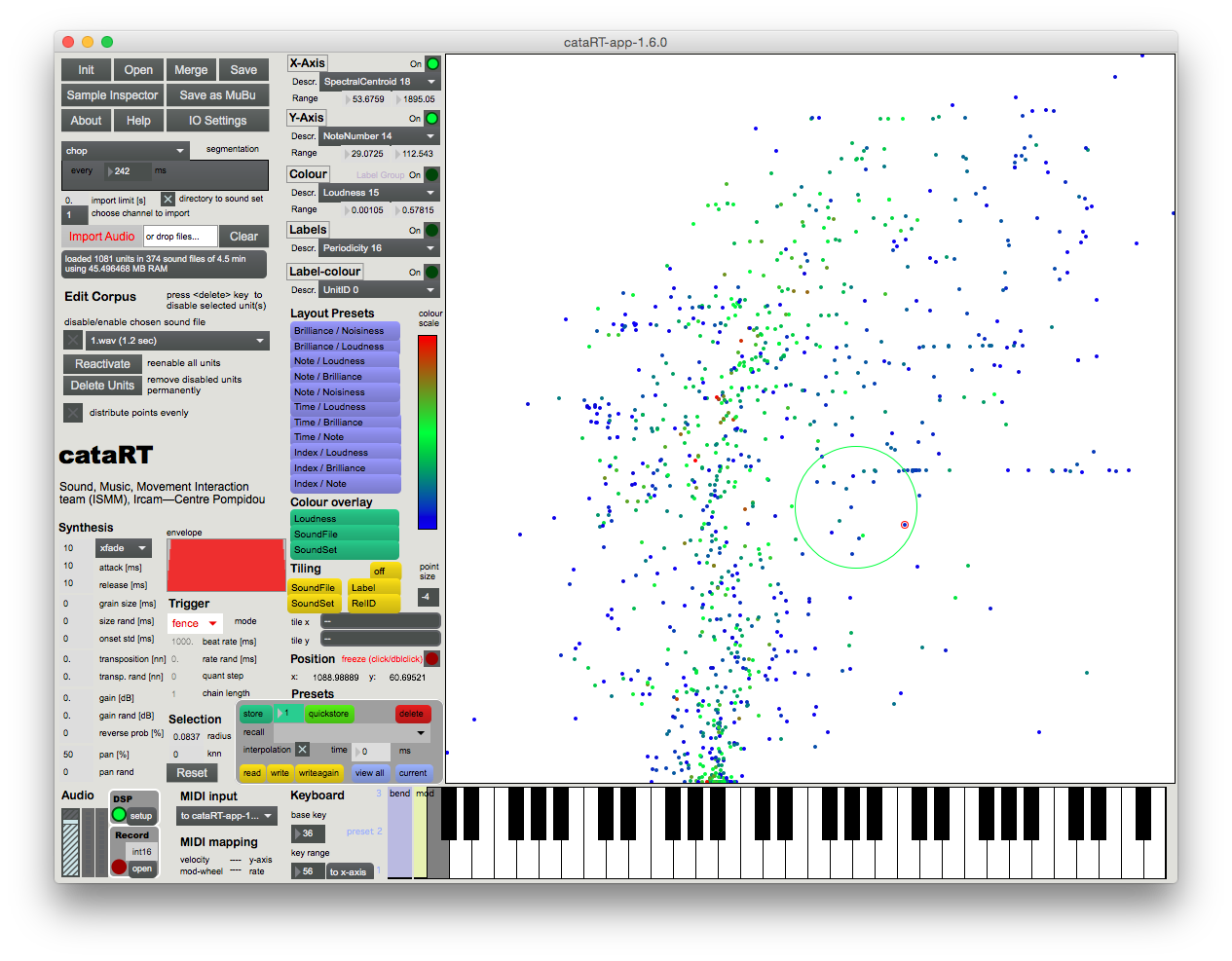 | CataRT Standalone Application | distributed by the Ircam Forum (Mac Intel/ARM) |
Of historical interest is the original CataRT classic (opens new window) from 2005, a modular patch system for Max/MSP with the FTM&Co. extensions (Mac/Windows, see also ftm.ircam.fr (opens new window))
# Videos
This video from 2010 shows how various sounds (train and voice recordings) are imported and browsed by timbre in CataRT classic (opens new window):
Here, several recordings of wind are used in the CataRT Standalone (opens new window) to recreate the temporal evolution of wind with varying strength and character (gusts):
# Support and Community
Discussions about features and issues takes place on the Forum discussion groups (opens new window), accessible from the respective CataRT Forum projects (opens new window).
# See Also
- CataRT as an expressive performance instrument, collection of audio and video examples
- Music and installations made with CataRT
- Corpus-Based Sound Synthesis Survey, ongoing web and literature study of approaches and advances in the field of CBCS