XMM is a portable, cross-platform C++ library that implements Gaussian Mixture Models and Hidden Markov Models for both recognition and regression. The XMM library was developed with interaction as a central constraint and allows for continuous, real-time use of the proposed methods.
Several general machine learning toolkits have become popular over the years, such as Weka in Java, Sckits-Learn in Python, or more recently MLPack in C++. However, none of the above libraries were adapted for the purpose of this thesis. As a matter of fact, most HMM implementations are oriented towards classification and they often only implement offline inference using the Viterbi algorithm.
In speech processing, the Hidden Markov Model Toolkit (HTK) has now become a standard in Automatic Speech Recognition, and gave birth to a branch oriented towards synthesis, called HTS. Both libraries present many features specific to speech synthesis that do not yet match our use-cases in movement and sound processing, and have a really complex structure that does not facilitate embedding.
Above all, we did not find any library explicitly implementing the Hierarchical HMM, nor the regression methods based on GMMs and HMMs. For these reasons, we decided to start of novel implementation of these methods with the following constraints:
We chose C++ that is both efficient and easy to integrate within other software and languages such as Max and Python. We now detail the four models that are implemented to date, the architecture of the library as well as the proposed Max/MuBu implementation with several examples.
The implemented models are summarized in Table the following table. Each of the four model addresses a different combination of the multimodal and temporal aspects. We implemented two instantaneous models based on Gaussian Mixture Models and two temporal models with a hierarchical structure, based on an extension of the basic Hidden Markov Model (HMM) formalism.
| \ | Movement | Multimodal |
|---|---|---|
| Instantaneous | Gaussian Mixture Model (GMM) | Gaussian Mixture Regression |
(GMR) Temporal | Hierarchical Hidden Markov Model(HHMM) | Multimodal Hierarchical Hidden Markov Model(MHMM)
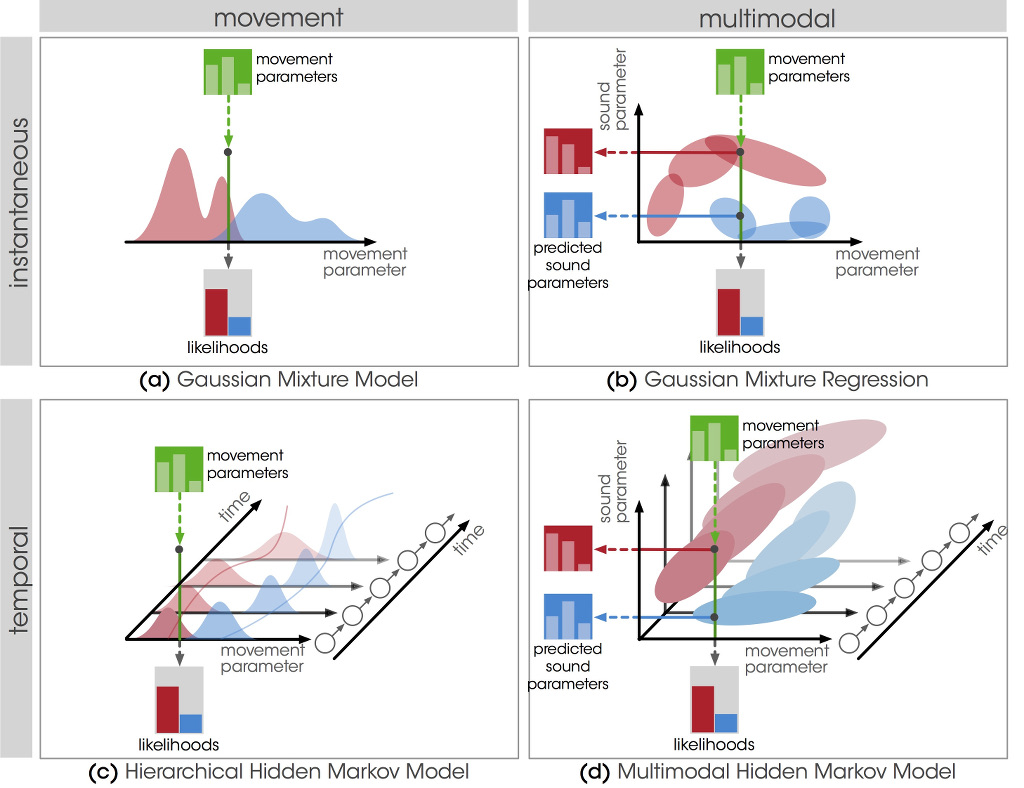
implemented models"
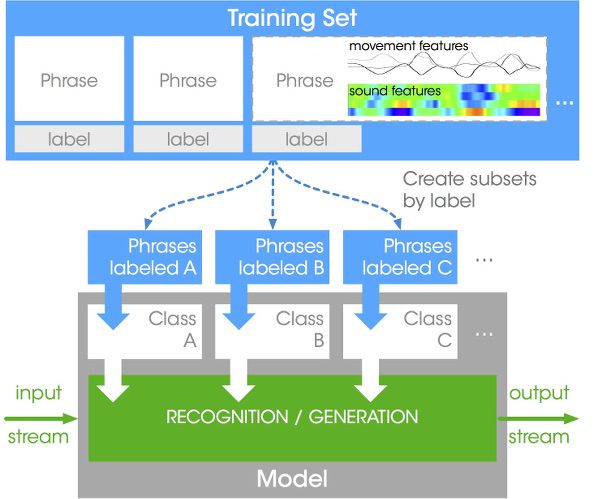
Our implementation has a particular attention to the interactive training procedure, and to the respect of the real-time constraints of the performance mode. The library is built upon four components representing phrases, training sets, models and model groups, as represented on Figure 2. A phrase is a multimodal data container used to store training examples. A training set is used to aggregate phrases associated with labels. It provides a set of function for interactive recording, editing and annotation of the phrases. Each instance of a model is connected to a training set that provides access to the training phrases. Performance functions are designed for real-time usage, updating the internal state of the model and the results for each new observation of a new movement. The library is portable and cross-platform. It defines a specific format for exchanging trained models, and provides Python bindings for scripting purpose or offline processing.
J. Francoise, N. Schnell, R. Borghesi, and F. Bevilacqua, Probabilistic Models for Designing Motion and Sound Relationships. In Proceedings of the 2014 International Conference on New Interfaces for Musical Expression, NIME’14, London, UK, 2014. Download
J. Francoise, N. Schnell, and F. Bevilacqua, A Multimodal Probabilistic Model for Gesture-based Control of Sound Synthesis. In Proceedings of the 21st ACM international conference on Multimedia (MM’13), Barcelona, Spain, 2013. Download