TODO.
Several examples are included in the ipython notebook IPython Notebook: python/examples/QuickStart_Python.ipynb
We report here the static html version of the notebook:
See http://ircam-rnd.github.io/xmm/
The python library reflects the sructure of the C++ library. The same classes and methods can be used on both implementations. First, import the python library (needs to be within your Python search path).
import xmm
In this example, we illustrate the process of training and classification with Gaussian Mixture Models. We have 3 data files called "gmm_test_data1.txt", "gmm_test_data2.txt", "gmm_test_data3.txt". Each file contains a 2D array where each row is a data frame with 6 dimensions. The data was generated with the example patch from the Max/Mubu implementation (see http://julesfrancoise.com/mubu-probabilistic-models/)
First, we need to record and annotate the training data. This is done using the TrainingSet class:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
# Create the training set
training_set = xmm.TrainingSet()
training_set.dimension.set(6) # dimension of data in this example
training_set.column_names.set(['a', 'b', 'c', 'd', 'e', 'f'])
# Record data phrases
for i in range(3):
phrase = np.genfromtxt('data/gmm_training_data{}.txt'.format(i+1))
training_set.addPhrase(i, str(i+1))
for frame in phrase:
# Append data frame to the phrase i
training_set.getPhrase(i).record(frame)
For most objects of the library, calling the print function from python will print the JSON file description of the current object. In this case, we can have a look at the data contained in the training set:
print "Number of phrases in the training set: ", training_set.size()
print "Labels: ", training_set.labels()
print "names of the columns of the training data:", training_set.column_names.get()
The training Set has 3 classes with integer labels 1, 2 and 3.
We can now train a GMM — i.e. a group of Gaussian Mixture Models with different class labels.
We start by creating an instance of the GMM, and we can then adjust the model parameters (number of Gaussians and regularization of the covariances) and train the models for all classes of the training set:
# Create a GMM (handles multiples labels for recognition)
gmm = xmm.GMM()
# Set parameters
gmm.configuration.gaussians.set(10)
gmm.configuration.relative_regularization.set(0.01)
gmm.configuration.absolute_regularization.set(0.0001)
# Train all models
gmm.train(training_set)
print "number of models: ", gmm.size()
The trained ModelGroup can be used directly to perform continuous recognition or classification with class-conditional GMMs.
We start by loading test data originatin from the same 3 distributions used for training:
# read test data (concatenation of 3 test examples labeled 1, 2, 3)
test_data = np.genfromtxt('data/gmm_test_data1.txt')
test_data = np.vstack((test_data, np.genfromtxt('data/gmm_test_data2.txt')))
test_data = np.vstack((test_data, np.genfromtxt('data/gmm_test_data3.txt')))
Then, we can set additional attributes of the models, such as the size of the window used to smooth the likelihoods, and initialize the "performance mode". We create several arrays that will store the normalized likelihoods and log-likelihoods during continuous recognition, and we can then perform the recognition continuously and causally by updating the recognition with each new frame of the test examples:
# Set Size of the likelihood Window (samples)
gmm.shared_parameters.likelihood_window.set(40)
# Initialize performance phase
gmm.reset()
# Create likelihood arrays for recognition
instantaneous_likelihoods = np.zeros((test_data.shape[0], gmm.size()))
normalized_likelihoods = np.zeros((test_data.shape[0], gmm.size()))
log_likelihoods = np.zeros((test_data.shape[0], gmm.size()))
# Performance: Play test data and record the likelihoods of the modes
for i in range(test_data.shape[0]):
gmm.filter(xmm.vectorf(test_data[i, :]))
instantaneous_likelihoods[i, :] = np.array(gmm.results.instant_likelihoods)
normalized_likelihoods[i, :] = np.array(gmm.results.smoothed_normalized_likelihoods)
log_likelihoods[i, :] = np.array(gmm.results.smoothed_log_likelihoods)
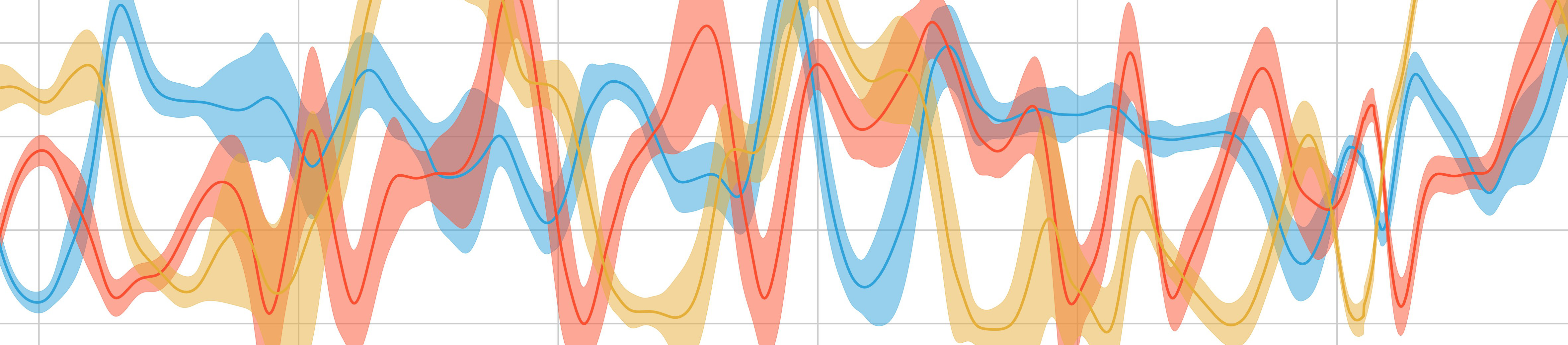
We can finally plotthe normalized and log-likelihoods over time:
# Plot the likelihoods over time for the test phase
plt.figure()
plt.subplot(311)
plt.plot(instantaneous_likelihoods)
plt.title("Instantaneous Likelihood of Each Model Over time")
plt.xlabel("Time (Samples)")
plt.ylabel("Likelihood")
plt.legend(("model 1", "model 2", "model 3"))
plt.subplot(312)
plt.plot(normalized_likelihoods)
plt.title("Normalized Smoothed Likelihood of Each Model Over time")
plt.xlabel("Time (Samples)")
plt.ylabel("Normalized Likelihood")
plt.legend(("model 1", "model 2", "model 3"))
plt.subplot(313)
plt.plot(log_likelihoods)
plt.title("Smoothed Log-Likelihood of Each Model Over time")
plt.xlabel("Time (Samples)")
plt.ylabel("Log-Likelihood")
plt.legend(("model 1", "model 2", "model 3"))

Note that the trained model can be saved to a JSON file:
gmm.writeFile("test_gmm.json")
This example is inspired by the test_hierarchicalhmm.y file in the python/examplesdirectory.
The data originates from the example patch: "hhmm_leapmotion_recognition.maxpat" of the Max implementation (see http://julesfrancoise.com/mubu-probabilistic-models/). The data represents the XYZ Speed of the hand extracted from the leapmotion, rescaled (divided by 1000) and smoothed (moving average filter).
# Create the training set
training_set = xmm.TrainingSet()
training_set.dimension.set(3) # dimension of data in this example
training_set.column_names.set(['x', 'y', 'z'])
# Record data phrases
for i in range(3):
phrase = np.genfromtxt('data/hhmm_test_data{}.txt'.format(i+1))
training_set.addPhrase(i, str(i+1))
for frame in phrase:
# Append data frame to the phrase i
training_set.getPhrase(i).record(frame) # Create a single HMM (group of GMMs running in parallel for recognition)
# Train the HMMs
hhmm = xmm.HierarchicalHMM()
hhmm.configuration.states.set(40) # <== try changing the number of hidden states
hhmm.train(training_set)
print "number of models", hhmm.size()
We consider a simple example of continuous recognition and folllowing with data originating from the concatenation of 3 recording, one from each class of gestures:
# read test data (concatenation of 1 example of each of the 3 classes)
test_data = np.genfromtxt('data/hhmm_test_data1.txt')
test_data = np.vstack((test_data, np.genfromtxt('data/hhmm_test_data2.txt')))
test_data = np.vstack((test_data, np.genfromtxt('data/hhmm_test_data3.txt')))
As before, we initialize the performance mode with the performance_init function and we can then proceed to continuous recognition where we update at each time step the model with the incoming data frame.
In this example, we store the instantaneous likelihood as well as its normalized version and the log-likelihood.
We also keep track of the "progress" within the model, which gives an estimate of the temporal progression of the current gesture.
# Initialize performance phase
hhmm.reset()
# Create arrays for likelihoods
instantaneous_likelihoods = np.zeros((test_data.shape[0], hhmm.size()))
normalized_likelihoods = np.zeros((test_data.shape[0], hhmm.size()))
log_likelihoods = np.zeros((test_data.shape[0], hhmm.size()))
progress = np.zeros((test_data.shape[0]))
# Performance: Play test data and record the likelihoods of the modes
for i in range(test_data.shape[0]):
hhmm.filter(test_data[i, :])
log_likelihoods[i, :] = np.array(hhmm.results.smoothed_log_likelihoods)
instantaneous_likelihoods[i, :] = np.array(hhmm.results.instant_likelihoods)
normalized_likelihoods[i, :] = np.array(hhmm.results.smoothed_normalized_likelihoods)
progress[i] = hhmm.models[hhmm.results.likeliest].results.progress
# Note: you could extract alphas and time progression as for HMM, for each model. E.g. :
# print np.array(hhmm.models[hhmm.results_likeliest].alpha)
We can Finally plot the likelihood of each model over time, which is estimated causally with a forward algorithm (therefore allowing a use in real-time). The last plot depicts the temporal progression within the likeliest model, which gives an idea of how the new performance of the gesture is followed in time.
# Plot the likelihoods over time for the test phase
plt.figure()
plt.subplot(411)
plt.plot(instantaneous_likelihoods)
plt.title("Instantaneous Likelihood of Each Model Over time")
plt.xlabel("Time (Samples)")
plt.ylabel("Likelihood")
plt.legend(("model 1", "model 2", "model 3"))
plt.subplot(412)
plt.plot(normalized_likelihoods)
plt.title("Normalized Smoothed Likelihood of Each Model Over time")
plt.xlabel("Time (Samples)")
plt.ylabel("Normalized Likelihood")
plt.legend(("model 1", "model 2", "model 3"))
plt.subplot(413)
plt.plot(log_likelihoods)
plt.title("Smoothed Log-Likelihood of Each Model Over time")
plt.xlabel("Time (Samples)")
plt.ylabel("Log-Likelihood")
plt.legend(("model 1", "model 2", "model 3"))
plt.subplot(414)
plt.plot(progress)
plt.title("Normalized progression with the likeliest model")
plt.xlabel("Time (Samples)")
plt.ylabel("Normalized Progress")
plt.show()
